Understanding SVM Classification: Step-by-Step Explanation | Machine Learning in Tamil

Support Vector Machine (SVM) is a powerful supervised machine learning algorithm used for classification and regression tasks. In this explanation, I will focus on SVM for classification.
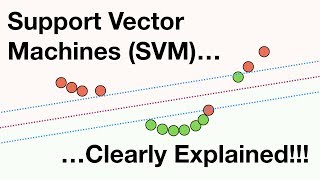
The primary goal of SVM is to find an optimal hyperplane that separates the input data points of different classes with the largest possible margin. The hyperplane is a decision boundary that separates the data into different classes. SVM can handle both linearly separable and nonlinearly separable data by using different techniques.
Here's how SVM classification works:
Input data representation: Each data point in the dataset is represented as a feature vector in an ndimensional space. For example, if you have a dataset with two features (x1, x2), each data point would be represented as (x1, x2).
Selecting a hyperplane: SVM aims to find a hyperplane that maximizes the margin between different classes. The margin is the distance between the hyperplane and the nearest data points of each class. The hyperplane that achieves the maximum margin is considered the optimal decision boundary.
Linearly separable data: If the data points are linearly separable, SVM finds the optimal hyperplane that separates the data points with the largest margin. The hyperplane is selected in such a way that it minimizes the misclassification of data points from either class.
Nonlinearly separable data: In many realworld scenarios, the data points may not be linearly separable. In such cases, SVM employs a technique called the kernel trick. The kernel trick maps the original input data into a higherdimensional feature space, where the data points become linearly separable. The algorithm then finds the optimal hyperplane in this transformed space.
Support vectors: Support vectors are the data points that lie closest to the decision boundary (hyperplane). These points are crucial in defining the hyperplane and are used to make predictions. The decision boundary is determined by a subset of support vectors that are located on or within the margin.
Classification: Once the optimal hyperplane is determined, SVM can classify new, unseen data points by mapping them into the same feature space used during training. The algorithm then predicts the class of the data point based on which side of the decision boundary it falls.
SVM has several advantages, including its ability to handle highdimensional data, robustness against overfitting, and effectiveness in handling both linearly separable and nonlinearly separable data. However, SVM's training time can be relatively longer for large datasets, and selecting the appropriate kernel function and tuning hyperparameters can be challenging.
Overall, SVM is a versatile classification algorithm that has been widely used in various domains, including image classification, text classification, and bioinformatics.