Understanding SVM Kernels: A Comprehensive Guide | Machine Learning in Tamil

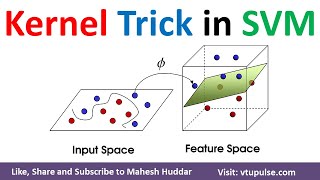
Support Vector Machines (SVM) are a popular class of supervised learning algorithms used for classification and regression tasks. SVMs use a technique called the kernel trick to transform data into a higherdimensional space, where it becomes easier to separate different classes. The kernel trick allows SVMs to work efficiently even in cases where the data is not linearly separable in the original feature space.
A kernel in SVM is a function that calculates the similarity between two input samples. It measures the dot product or similarity between the transformed feature vectors in the higherdimensional space. By applying different kernel functions, SVMs can learn complex decision boundaries that can separate classes more effectively.
Here are some commonly used SVM kernels:
Linear Kernel: The linear kernel is the simplest kernel and is often used when the data is linearly separable. It calculates the dot product between the input samples, which corresponds to a linear decision boundary in the original feature space.
Polynomial Kernel: The polynomial kernel computes the similarity as the power of the dot product between two samples, optionally adding a constant term. It can capture curved decision boundaries and is effective when dealing with polynomially separable data.
Radial Basis Function (RBF) Kernel: The RBF kernel is one of the most popular and versatile kernels. It measures the similarity based on the Euclidean distance between samples in the transformed feature space. The RBF kernel can capture complex decision boundaries and is effective in handling nonlinearly separable data. It is defined as:
K(x, y) = exp(gamma * ||x y||^2)
where gamma is a parameter that determines the influence of each training sample. A smaller gamma value makes the decision boundary smoother, while a larger value allows the model to capture finer details of the data.
Sigmoid Kernel: The sigmoid kernel calculates the similarity using the hyperbolic tangent function. It is commonly used in binary classification tasks. However, the sigmoid kernel is more prone to overfitting and is not as popular as the linear, polynomial, or RBF kernels.
Custom Kernels: In addition to the predefined kernels, SVMs also support custom kernels. A custom kernel allows users to define their own similarity measure between samples based on domain knowledge. This flexibility enables SVMs to handle a wide range of data types and problem domains.
The choice of kernel depends on the specific problem at hand, the nature of the data, and the desired decision boundary. It is often determined through experimentation and crossvalidation to find the kernel that yields the best performance for a given task.