Vision Transformers explained

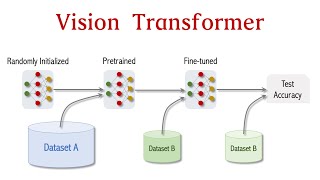
Vision Transformer, also known as ViT, is a deep learning model that applies the Transformer architecture, originally developed for natural language processing, to computer vision tasks. It has gained attention for its ability to achieve competitive performance on image classification and other vision tasks, even without relying on convolutional neural networks (CNNs).
Transformers: • Transformers for beginners | What are...
**************************************************************************************
For queries: You can comment in comment section or you can mail me at [email protected]
**************************************************************************************
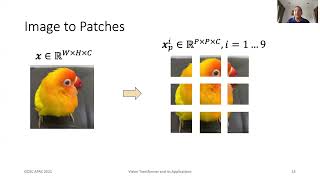
The key idea behind the Vision Transformer is to divide an input image into smaller patches and treat them as tokens, similar to how words are treated in natural language processing. Each patch is then linearly projected and embedded with position information. These patch embeddings, along with position embeddings, are fed into a stack of Transformer encoder layers.
The Vision Transformer has shown promising results, demonstrating competitive performance on image classification tasks, object detection, and semantic segmentation.
#computervision #transformers